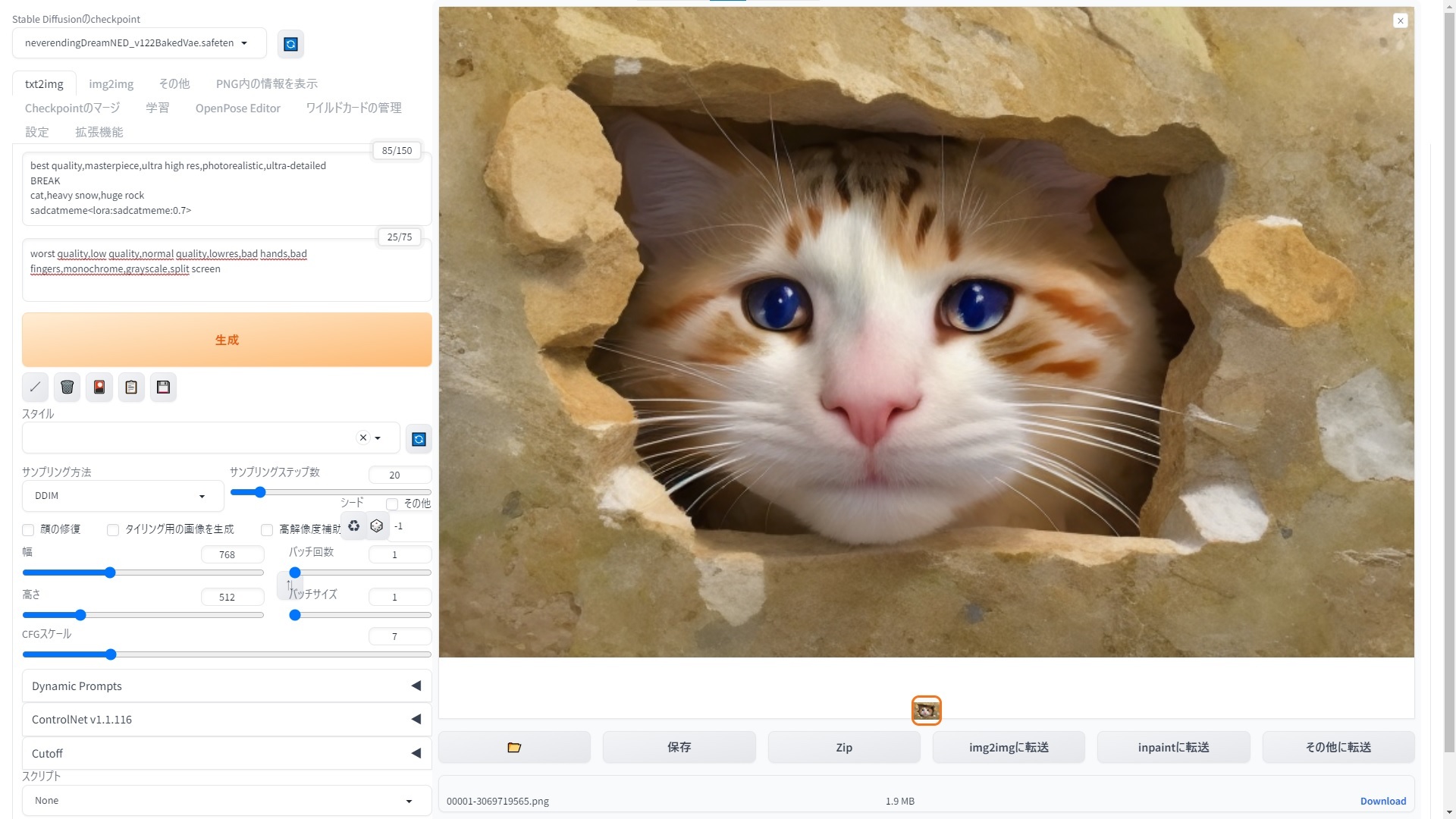
◎正当な理由による書き込みの削除について: 生島英之 とみられる方へ:Stable Diffusion YouTube動画>1本 ->画像>20枚
動画、画像抽出 ||
この掲示板へ
類似スレ
掲示板一覧 人気スレ 動画人気順
このスレへの固定リンク: http://5chb.net/r/software/1661568532/ ヒント: 5chスレのurlに http ://xxxx.5chb .net/xxxx のようにb を入れるだけでここでスレ保存、閲覧できます。
イラストレーターの絵を学習させて新作絵を描くAIに同人作家たちが激怒 「勝手にわたしの絵を使わないでください!」 [469534301]
http://2chb.net/r/poverty/1661781605/ LINEでAI画像生成「お絵描きばりぐっどくん」 日本語に対応、Stable Diffusionを使用
https://kai-you.net/article/84593 関連スレ
Midjourney】AI画像生成技術交換3【StableDiffusion
http://2chb.net/r/cg/1661762186/ >>6 黒い画像しかできないんだがスペック不足?
1660Ti6Gじゃどうにもならんかね
>>9 確かGRisk版GUIはバグかなんかで1650と1660では上手く動作しないことが報告されてたと思う
>>10 そうなのか大人しく更新待つわサンクス
SDとか出てきてパワーのあるGPU買う理由が一つ増えたのは嬉しい
ちゃんと読んだらトップページに書いてあったな申し訳ない
>>9 Optimized Stable Diffusion GUI Tool使ってるけど、アプデして相性解決するチェック入れたら1660で動いた
https://booth.pm/ja/items/4118603 1660じゃなくて、ちゃんと確認したら1660Tiだった。
NMKD Stable Diffusion GUI - AI Image Generator
https://nmkd.itch.io/t2i-gui これのためにグラボ新調したいのだが
むずいな~
>>17 「今のところ(2022年9月2日現在)」はそうだね。
巨大なテンソルをメモリ空間に展開する必要があるけど、計算自体は単純だから、当分処理速度よりRAM容量という傾向が続きそうな気がする。
ただ、これから出てくるソフトウェアが何を求めるか、誰にわかるだろう。仮想通貨でも、大容量ハードディスクを使って計算をスピードアップするような手法も現れたよね。
個人的には、メインメモリに十分な空きがあれば、そちらで代替することもできるような気もする。かなり速度は落ちるけど、例えば50G必要となった場合、そっちの方が圧倒的に安価だし…
【画像】AIさん、また絵師を殺す。オープンソースのソフトの使い方が広まったところすごい勢いで2次元絵が進歩 [712093522]
http://2chb.net/r/poverty/1662129970/ >>21 これ最後の絵がまんまブルアカの水着チセの立ち絵になってるけどどのへんがすごいの?
ローカルで動く奴、Ver3.11入れたらちゃんと画像生成されるけど
こういう意味不明なのが出てくること多すぎるけど
こういうのはこれで味あってなかなか面白い
ただ7年前のグラボだから時間かかりすぎる。512x512の50stepで3分弱
ドリキンのStableDiffusion 自己インストールでの自己満デモ動画の 1:04:40 リック・アストリー 頻発って
ツイに上がってる浮世絵風のマイケル・ジャクソン好きだわ
ドリキンさんとか 清水さんとか ぜんさんとか その辺 過去の
ナンセンスにエロも求めると そこには 見たことある感じ アイコラ とか。w
無料で画像生成AI「Stable Diffusion」をWindowsに簡単インストールできる「NMKD Stable Diffusion GUI」の使い方まとめ、呪文の設定や画像生成のコツがすぐわかる
https://gigazine.net/news/20220902-nmkd-stable-diffusion-gui-usage/ >>26 リックアストリー俺も唐突にでてきたなw
それだけ4つ出たこともあるし、どっちかというとエラーとかじゃね
GitHub - mika-f/nekodraw: NekoDraw: CLIP STUDIO PAINT plugin for executing Stable Diffusion txt2img and img2img processor
https://github.com/mika-f/nekodraw オープンソースに有料ソフトのフォトショやらクリスタやらがすり寄って来るの気持ち悪いな
adobeとかがプラグイン作ってるんじゃなくて、誰かが勝手に作ってるだけでしょ。それをすり寄りだなんて
Photoshop用に公開されてるプラグインはAdobe自身が審査している
審査って意味知ってる?
amdは radeon edition for windowsを早急に作るんだ
>26 >32
>>38 ROCmがLinux専用だからなあ
AMDやる気なしでNVIDIA一択になってしまってる
>>37 直接Adobeは関わっていなくても審査するならAdobe公認というお墨付きを与えることにはなるだろ
却下しないのは当たり前だがこんなに早く企業のソフトに組み込まれるのを訝しむのがおかしいか?
むしろ逆にAdobeとしてはStableDiffusionを独占したくてたまらんのだろうなぁ
adobeくらいになると
適当な英単語で日本の女子高生の脚みたいなのを入力したら盗撮画像っぽいのできたわw
1060の6GでGRisk版GUI使って576x512の画像を生成してる時にVRAMの使用率見てみても50%ほどしか使ってないんだけど
>>45 うちはRTX2070SだけどVRAM8GBの8~9割くらい使って512*704の画像出すよ
GRiskの配布ページを見ると3日前にアプデされてるからフリー版に制限かけた可能性あるね
ここはPatreon有料会員になると大きいサイズを出せる最新バージョンが入手出来るらしいし(ユーザーコメントに書いてあった
ごみプロンプト買わされたと思ったら次はSDにまで金払わされるのかw
日本語入力したらsd向けのプロンプトに変換してくれる程度の特化なら期待できるんだけど
今AIお絵かきに一番喜んでいるのは
NMKDやばいな
テクスチャにするための継ぎ目のない画像とか
AI画像生成ツール「Stable Diffusion」「Midjourney」を使ったイラスト集が早くも発売
852話氏が生成・リファインしたイラスト100枚以上を収録、約半数には「呪文」も掲載
https://forest.watch.impress.co.jp/docs/bookwatch/news/1441883.html >>54 純粋にイラスト集として買うより、
作例の参考資料として買う人のほうが遥かに多そうw
アマのレビュー見た限り、参考資料としてはダメみたいだね
顔が画面の上に見切れることがやけに多いけど、やっとその理由を思いついたわ。
NMKDインストールしたのですがGPUを認識できない?みたいな表示が出てきます
当方RTX3060を使用してるのですがNMKDインストールするだけではダメなのでしょうか?
逆さまにテーブルに置かれたコップの中に白煙がたなびいてるイメージを出力したくて、色々と試してみたけど上手くいく気配がありません。
コップをひっくり返すことさえできないとは、情けないのは私なのかAIなのか。
"an overturned glass which captures curled white smoke in it, centered, realistic"
で、12枚出力した結果。
https://imgur.com/pZXCZeo 一番下の真ん中の画像は、ひっくり返っているように見えなくもないけど、コレジャナイ感が半端ない。
どなたかコップをひっくり返すpromptをご教示くださいませんか?
アルミ缶の上にあるみかんもうまいこと描写できなかったな
キャラと絵柄を維持したまま出力できるのはいつだろうな
NovelAIなら同じキャラの別の絵も出しやすいみたいよ
描く人ほぼいない昔のマイナーキャラを生成できたらいいなあ
その内同じキャラの差分を作る専用のAIとか、不完全な絵を修正して仕上げるAIも出てくるだろうね
【朗報】お絵描きAI、ラーメンの絵が描けないと判明 これでAIと人間の区別が容易に [206389542]
http://2chb.net/r/poverty/1666065315/ novelaiの学習データ、こっそりどこぞのdiffusionに統合されないかな
【画像】AI、ついに13人がラーメンを食べる最後の晩餐の生成に成功してしまう [579392623]
http://2chb.net/r/poverty/1666268558/ 違うそうじゃない
AIとコラボして神絵師になる! 「Stable Diffusion」などを仕事や趣味に使える技術の解説書が発売
AI画像生成の法的な側面やプロのお仕事での活用事例も掲載
https://forest.watch.impress.co.jp/docs/bookwatch/news/1450555.html >>70 日進月歩の画像生成AIを、固定的な書籍で解説しようとする点でセンスが無い。
原稿執筆当時の記録という意味では、後世価値が出るかも。
not imageなんちゃらって出て何も生成されないんだけど何でかな?
エスパーではないので何を使って何をしようとしたのか書かないと答えようがないよ
>>73 ありがとう、、NMKD Stable Diffusion GUI 1.6.0をインストーラで問題なく入れ終えたんだけど、画像生成すると何故かnot
image generate って文字だけでて 何も生成されない
CORE i5 RTXさ3060Ti
まあ一般的に利用しようとするとまず限定的なスペックなマシンの用意のほうが面倒だから
どうしよう
>>76 出力しようとしてる画像の解像度が大きすぎると黒い画像になることがある
512x512とか512x768で試すんだ
エスパーしてみる
VRAM8GB超える解像度の画像生成してるんだろうな
>>77 デフォルトで512×512だが真っ黒だ
試しに128×128とかでも試したがやはり真っ黒
>>78 >>79
エラーメッセージの類は出てなかったはず
英語分からない民だけど、各種ソフトのインストール作業中、「Error」などの英単語が出ないかどうか1行ずつ確認していたから間違いない…はず多分
画像生成中にタスクマネージャーを見てみると、GPU使用率は3~4%ほどだった
1位はFirefoxで、2位はiTunesで、3位はデスクトップウィンドウマネージャー
あれ、もしかしてSD君はGPUを使ってないのか…?
絵が出ない人だいたいモデルを入れてない説
SD使いだしたばかりの頃Promptの仕様理解せずに適当にぶち込んでいたら真っ黒な画像が生成された事あったな
パイソンだかのプログラムとかわかんねえけど
>307
>>76 >>80の者ですが、問題が解決しました!
以下のページでトラブルシューティングを見ると、解決方法が載ってました
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Troubleshooting#green-or-black-screen )
これによると、webui-user.batをメモ帳で開いて、「set COMMANDLINE_ARGS=」の後に
「--precision full --no-half --medvram」という文字列を打ち込めば良いらしい
その通りにしたら無事に解決しました
いやぁ、一時期はStable Diffusionという文字すら見るのも嫌になりかけたけど、あっさり解決して良かった
「Stable Diffusion」がメジャーバージョンアップ ~画像の深度情報を推測可能に
学習モデルを刷新、超解像アップスケール機能も
https://forest.watch.impress.co.jp/docs/news/1458747.html 「Depth2img」で左の画像を入力し、右の複数の画像を生成した例
「クリスタ」は画像生成AI搭載を中止 ~ユーザーからの反対意見を尊重
「画像生成AIパレット」を実装しないv1.13.0無償アップデーターが公開
https://forest.watch.impress.co.jp/docs/news/1461108.html AUTOMATIC1111って待ってればいつかSD2.0にアップデートされる?Google Colabっての使った方法じゃないとアップデートできないの?
自分のGPUじゃ学習するにはメモリが足りないから少しガッカリしたけど、学習済みのモデルを利用した生成でも十分すごかった
>>89 2.0の768x768、depthモデルはすでにWeb UIで使えるよ
stable diffusion GUIで数日間、自分の顔を変換しようとしてるんだが、
>>97 【StableDiffusion】AI画像生成技術12【NovelAI】
http://2chb.net/r/cg/1670898879/ Denoising strengthは上げれば上げるほど変化が大きくなるものだけどな。
>>98 ,99
ありがとうございます。
もうちょっと、あがいてみます。
2枚の画像の中間画像を補完してちょっとした動画を作りたい
ぶっちゃけもうあるけど使い易いものではないよね
>>58 グラフィックドライバが古いとGPUを認識しない事がある
cuDNNやCUDAToolkitは無くても動く
どこで追加学習されたものだか分からないけど、プライベートな記念写真、盗撮っぽいポルノや児童の裸体みたいなものまでほとんど無加工の状態で出力される。どこで何を学習してんの?これって
人間の裸体なんて、概念としてはむしろ衣服よりも簡単でしょ
例えばディズニーランドで絵を生成すると、客の写真がそんなに低くない頻度で、ほぼ無加工で出てきたりする。アダルト系ではないキーワードで、女児の裸が出たりする。解決しないと潰されたりすると嫌だから、解決してくれ
まずそれが実在する客が確実に過学習で出ているのでなければ問題ないし、
鍵かけ忘れのクラウドストレージに自動で上がってるやつは学習したらまずそうだが、学習してないことを祈る
吉幾三って海外進出したら OK Let’s go になるの?
日本人の実写はうまくいかないね。なんでみんなうまいんだろ。
webUIのやつ入れたんだけど
>117
>>118 多分それやったんすけど綺麗にならなかったんですよね
モデルのせい?
>>119 どうやってマスクしたのかここに画像を貼ってくれ
>>120 貼るのは控えたいんですけど
文で説明すると服に被せて塗った感じ
きっちりと言うよりは少しはみ出してマスクしたかんじ
>119
>>122 こんな感じ
呪文が具体的じゃない?
青に変化とかじゃ無理か
みんなどこで使い方学んでるんや
今の最先端はどんな感じですか
>>123 img2imgは元の色が強めに出るから、マスク内のズボンの色を変えるというのは難しそう
ペイントソフトでズボンの膝から下を単色でいいので目的の色で塗ってから、それをimg2imgにかけると質感が出るかも
参考
より思い通りの画像を作る!img2img&フォトバッシュ複合ワークフローについて[StableDiffusion]|abubu nounanka|note
https://note.com/abubu_nounanka/n/n3a0431d2c47a より思い通りのAI画像を作る!inpaintと複数モデルの使い分け[StableDiffusion]|abubu nounanka|note
https://note.com/abubu_nounanka/n/nee6c21ff84e6 >>127 ありがとうございます!!
やっぱ色々やり方があるんですなあ
呪文だけでも大変なのに笑
昨日t2iでエロ娘大量に作ったけど、ここからどんどん実用的ツールができてくる予感はするね
d2iとかi2iを駆使したら結構なことができそう
だけど、基本は思い通りの絵が出せるツールではない
>>127 この人のnoteは目的の絵に寄せていく方法が書いてあっていいね
AI絵をツールとして活用する方向の発展形はこういう方法論が蓄積されてphotoshopみたいなアプリに統合されていくんだろうね
SDの画像生成方法の解説を見るとモデルによる推論だけでデータ生成してるような説明なんだけど、これプロンプトからt2iで生成させるときってどこかのイメージ検索も援用してる?
>>130 生成時に参照しているのは学習モデルだけだよ
YouTubeが重くなったのは動画の再生にGPUアクセラレーションが使われているからで、ネットワークが重くなったわけじゃないよ
特定のキャラ絵の生成やってみたいんだけどLoRAで上手くいかなくて困ってます
>>133 【StableDiffusion】画像生成AI質問スレ02【NovelAI】
http://2chb.net/r/cg/1677430973/ 最近知ったんだけどすごいな
Bstaberてのも良いよ。M字開脚になりがちだが
これ英単語にしか対応してないのか
日本語でもできるけれども
そうなのか
開発元のStability AIが日本法人立ち上げてるみたいね。将来性どうなんだろう。
商業利用する場合はカネ取るんじゃね?
一寸先は闇だ
civitai落ちてるんだけどよくあること?
>>143 Stability AIは去年の10月に1億ドルの出資を受けてるよ
Stable Diffusionをオープンソースで提供して、AI関係の技術力を世界中にアピールできたからね
オイル肌になる呪文と設定で好きなグラドルの画像をi2iしたらテカテカ好きの俺の性癖にブッ刺さる画像できてしまった
AUTOMATIC1111版をcolabで動かしてたんけど、さっきからUIのURL開いても504 Gateway Time-outになる
nsfwをネガに突っ込んどけばとりあえず裸になりづらくなったような
nsfw: 職場閲覧注意
Stablediffusionwebでなんか具体的な生成の画面が出ないんだ俺だけ?
モデルが悪いんじゃない?ヌード専門みたいな学習させてるのあるよ
512よりも画像サイズを上げるととたんに画像が崩れるのなぜなんでしょう。
512が1.5の学習ソースなのはそうだけど
2048とかめちゃデカにすると大体バケモン生まれるわ
リアル人間を生成するには何GBのモデルが必要なんだよ。。。
すげえ
Instant neural graphics primitives
https://github.com/NVlabs/instant-ngp Making a NeRF animation with NVIDIA's Instant NGP
ダウンロード&関連動画>> VIDEO 女優のlora使ってもあんまり顔が似ないんだけど何が原因かわかる人いますか?
>>171 女優ロラッテプロンプト書いてなくないか?
それにないわと思うんだけど
>>171 Hires.fixをオンにしてdenoisingを0.5くらいまで上げて
AVは検索したらコラじゃない本人の画像があるからなぁ
女性だけならそこそこのクオリティだけど男と絡ませようとするとやっぱ落ちるな
他のパラメータ変えないでサイズだけ縦に伸ばしたりするとかなりポーズとかかわるな
512x512の画像をデータベースにしてあるらしくそれより大きい画像作るとおかしくなる。最近のは768x768のもある。
縦や横に延ばしたいときはバリエーションリサイズ、出力された画像を大きく出し直したいときは高解像度補助を使うのよ鉄郎
めっちゃ盛り上がってるだろうと思ってスレ来たらなぜこんな静かなんだ
質問は 質問すれで
Easy Diffusion 2.5
The easiest way to install and use Stable Diffusion on your own computer.
https://github.com/cmdr2/stable-diffusion-ui >>187 stable diffusionは元々そっちが最初
SVO+助詞くらいの単文なら理解するしその方が複数オブジェクトのコントロールが効く
a cat eats a mouse. は理解できなかったよ
>>191 girl giving blow job
は理解できるよな
最近使い始めたけど、RadeonVega64(6年前発売)の6Gメモリでも動くんだな
同じ呪文でも、違う絵になるのね
AI凄いっていうけど、seed値というものが存在してる時点で世界乗っ取りとかはまだ遠そうだよな
SEED値が同じでも、プロンプト少し追加したら全然異なる。
たまーに当たり画像が出てくるんだよな
実写系ははずればっかだけど二次絵になると当たりばっかで延々とぶん回しちゃうわ
個体差があるからわかんない
謎建造物とかぐっちゃぐちゃの足だけの化物が出る時ってどういう設定にしたら抑えられる?
リアル向けネガティブ
一生懸命プロンプト並べてもモデル作者がその言葉でタグ付けてなきゃ意味ないんじゃないの?
やった事あればわかるだろうけどタグ解析するとblurryとかは普通に追加される時ある
pixivの画像に、同じ顔でいろんなポーズのがあるけど、呪文を一個でも追加すると顔も変わってしまうんだが、どうやって同じ顔で作れるの?
>208
>>196 AIを含めた非可逆圧縮・展開の数学論理では、計算式に必ず自然乱数が加算される構図になる
この自然乱数の部分をとある数値(0.0とか)に固定すると、可逆圧縮になる
可逆圧縮は元に戻せるという意味だから、乱数部分を固定すると答えが1つしか出せなくなる(もとは1つしかないので)
seedを固定すると同じ絵しか生成できない数学的理由がこれ
(seedは元のノイズ絵を生成するための固有値で、この数字を固定すると同じノイズ絵を生成するよう設計されているから)
>>199 プロンプトはseed以外で「人間が与える乱数」
その乱数に強い方向性があるから特徴として現れる
人間が与える乱数に大きな矛盾があれば、生成絵も矛盾が出る
同じ顔を与えれるだけの乱数の方向性を与えれば同じ顔にはなる
ただ、現時点ではpromptだけでは無理だと思われる
>>204 矛盾をゼロにすればいい
モデルの適性を超えたレゾリューションで生成すれば、勝手に破綻しやすくなる
(数学的処理をやってるAIは、三角関数的思考で空いた部分を繰り返そうとするので)
>>206 逆に、どれかがヒットすればその特徴が採用される(Negativeならその特徴が忌避される)
モデルがどのタグで学習させてるかわからないなら、むしろ思い当たるものすべてを無制限に並べ立てた方がいいということになる
ちなみに、bad_anatomyはdanbooruで11000枚程度ある
タグ付けるわけないというのは思い込みでしかないと思うよ
>>209 LORAって、そういう使い道だったのか
助かります
>213
何しても色が薄くなるようになっちゃって再起動とかしても直らなくて困ってます
生成途中(50%,60%...)ってなってる時は鮮やかな色なんですが
>>216 ・VAE
・過剰(cfg,promptなど)
ありがとうございます、でもVAEをオフにしても
モデルとVAEが合ってないんじゃないか。
適当な画像編集ソフトで彩度上げればいいだけの話じゃないの
モデル変えてみたらカラーになりました!と思ったら
>222
>>223 めっちゃ助かりました!!!!
VAEじゃないファイルをVAEのとこに入れたりわけわからない事してました
それでVAE入れたら普通にカラーになりました!!!
VAEの切り替えの設定もそのようにしました!
ご丁寧に有難う御座います!!!!
VAE当てると画像が綺麗になるけど細かいディテールが微妙に潰れるのがね
色調・明暗・コントラストなどは一発で決まることなんて無理なんだから後から画像編集ソフトでやりゃいいんだ
そんな面倒なことする必要はない
早く飲みたくなったらお酒、眠たくなったらベッド
AIの会話能力はすごく進歩してて、文字会話であればほとんど人間と区別がつかないレベルまで来てるんだから、希望を会話で伝えるのは技術的には可能なんだよな
>>185 利用者少ない?
情報漁ってもAUTOMATIC1111のばかりヒットする
芸能人の名前を入れるだけでヌード生成できるように早よなれ!
美人過ぎたり化粧濃過ぎるのばっかだからその辺の地味顔のエロ生成してほしい
>>236 色々と学習させたり質の高いやつを作るには
それなりに技術が必要じゃん?
キミの知見や技術は知らんよ
ちょっと初心者の質問
モデルデータに画像データ自体は入ってない
呪文だけじゃなかなか思い通りのポーズにならないな
なるほど、、、
>>242 AIにも聞いてみたけどテンソルデータが入ってると
意味わからんからテンソルって何か小学生にも分かるように言うてくれや
と言ったけど小学生には難しいかもしれませんといわれた
そこまで言われると少しは勉強したくなりました
テンソルはベクトルのもうちょい高度なものと考えればいいよ
普通の画像だってデジタルなら1と0の連なりであって実体としての画像があるわけじゃないよね
>>241 中身見れるユーティリティあったような気がするが
AI未経験だけどloraってやつでキャラクターを学習させてイラスト生成をやってみたいんだけどプログラミングとかの知識はいらない感じ?
>>249 ありがとう
昨日から調べはじめたけどちゃんと一式インストールすればある程度はつくれそうね
ポストの情報とシードとかモデルのハッシュまで同じにしてるのに出力違うのはなんでだろう?
>>251 同じのを作りたければコピーをすれば良い
>>251 pink板かどっかで同じような話みたけど、A1111の設定のどこかのチェックボックスのON/OFFとかでも
出力変わったりするらしい
clipskip数値でも全然違うのでてくるしな
生成データをちゃんとインポートできてないだけじゃね?
>>251 あれが生成情報の全てではないから
起動オプションでも絵柄変わる物があるし
additional network経由だと使ったloraが残らない
ただのネガティブプロンプトの文言に見えるものが実はTlとかもある
googlecolabとWebUI両方試したけど、WebUIだとサイズ700×700くらいですぐ固まっちゃう
顔修復の重み設定って0が最大で1が最小だということに今気づいた
そんなことよりさ、誰かこういう拡張機能作ってくれ
>>264 ステーブル ディフュージョン WEB UI のことだったら
WEB UI なんで Web プログラミングすれば良い
実写用の衣装loraってどう作りゃあいいの?
>>267 すまん、知らんかった
ちょっと使ってみるわ
restore faceとかネガティブプロンプト当ててもだめだった
xyz plotやってみてるんだけど、もしかしてこれって全画像が1枚につながって出力されるわけ?
縮小されて出てくんの?
ちゃんとバラで生成されてるわ、よかったよかった
>>262 この動画を見た多くの人が「踊ってる女の子」って打ち込んだらこの動画が出て来ると勘違いしてそうで恐ろしい
>>275 スローで見たけど、手で隠れてるだけに見えるぞ
不自然といえば膝の辺りだけど、実写にちょっと加工施せばAI動画みたいになるじゃんと同時に思う
同じ描画の口開いてるverと閉じてるver作る場合、シード値固定してハイレゾ0.2~0.3とかが良いのかな?要は立ち絵欲しいんだけど他に良いやり方ある?
chatGPTに
>>279 StableDiffusionに詳しくないので
いい方法かどうかわからないけど
口の部分を隠した画像を読ませてガチャるという方法がある
>>279 口を閉じた画像ができたらそれをinpaintへ送り、口だけマスクして
「masked content(マスクされたコンテンツ)」は「fill(埋める)」
「inpaint area(inpaintを行う領域)」は「whole picture(画像全体)」
プロンプトは「閉じた口」を「開いた口」に変える
これでいけました
(txt2imgで生成)
(img2imgのinpaintで生成)
画像はメタデータ入りなのでPNG Infoに直接ドラッグ&ドロップすればパラメータが読み込まれます
質問はこっちのほうが人が多いですよ
【StableDiffusion】画像生成AI質問スレ9
http://2chb.net/r/cg/1682213108/ >>283 おぉぉ!凄い!これを知りたかった
今日早速挑戦してみます
あざす
通りすがりだけど、おかげでインペイントの使い方がわかったわ
メタデータ保持させるとなんか悔しいからjpgにしてるンゴ
ツイでタグ検索したらAIグラビアばっか出てきて萎えるわ
ガッキー作ってたらエビちゃんができた
グラボによって、全く同じ設定でも吐き出す絵が違うって以前どっかで見たんだけどマジ?
インペイントの件
>>296 メモリマッピングの違いで異なる場合はある
xformersやmedvram設定などはその影響を受けている
丸め誤差の収束方法で違いが出ることがある
サンプリングの「_a」付きはその影響を受けるものであるという意味らしい
完全バニラな理想状態では理論上異なることはない
(アーキテクチャ自身は内部で捻出した乱数を使っていない)
高収入のバニラですね知ってます
初歩的な質問で申し訳ない
お気に入りの顔が出てきたけど、LORAで学習させるには、20枚とか必要みたいで、ガチャで同じ顔を出しまくるまでやるしかないですか?
>>304 pnginfoで希望する画像の情報をt2iに転送
seedを固定(t2i転送の時点でそうなってる)して、右にあるExtraをチェックオン
Variation seedを-1に、Variation strengthをお好みの数値に
これで学習させたい枚数の4倍程度出力させたら希望に沿える状態になる?
一度お試しください
masterpieceが完成するまでにmasturbationに至ってしまうんだが世の作家もこんな気持ちなんだろうか
Loraのトリガーとか、あれはおまじない程度と思っといていいのかな。
埃被ってたゲーミングPCに入れてみたけどすげえなこれ。100枚くらい生成するまで本当に生成してるの信じられんかったわ。
特定の人物の顔とかだったら必須
トリガー、使ったほうがいいとは思いつつ、単純に覚えられない。
>>313 その手間をやってるんだったら、もうひと手間
LoRAファイルと同名のtxtファイルを作成し、そこにトリガーワードを記述
作ったtxtファイルをLoRAファイルと同じフォルダに移動
こうすれば、花札の画面で一目瞭然になる
txtはそのまま表示されるので、注釈を書いておいてもいいし、サイトの説明文を書いておいてもいい
>>313 追加
花札画面に表示されたテキストをドラッグで選択できるので、コピー(CTRL+C)でOK
こういうAI絵描きってフリー素材絵を生成できるの?
>>315 テキストファイル作っとくと、サムネの下にひょうじされるんだね。
これでだいぶ便利。有難う!
たまに明らかにAVのパッケージ画像を学習したやつ出てくるな
導入した時より、パフォーマンスが落ちるのが早くなってきてる気がする。
浅学が想像でテキトーなこと言いなさんな
キミの間違いを諌められているだけであって、議論なんて誰もしていない
初心者なんだが
>>325 ワイも初心者だけど、xformers導入してると変わるって聞いたことある
seedはあくまで最初のノイズ生成に関わる値ってどこかで見た
>>322 そんなこと言い出したら
日本語の書き方から説明しなくちゃいけないのか
自己解決した
導入後再起動したはずだが改めて再起動したら治ったわ
>>326 サンクスxformersは導入してる
最初のノイズが一緒でその後の除去過程が同じつまりvaeとプロンプトその他設定がもろもろ同じなら生成結果に大きな影響はでないはずだよ
久しぶりに更新来てたけど拡張が使えなくなったとかそういう話はあるのかしら
WEBUIの初回起動時
自己解決した
Python 最新版3.11でインストールしたらERRORでた
3.10.9でも動いてるけどなんかダメなんかこのバージョン
動くんならええ
>>333 そうそう、インストール時は止まって見える時間がけっこうあるんだよ
でも1時間は長いね
うちのRyzen 5 3600/32GBで10分かからないくらい
Twitterでbrav5とかいうのがめっちゃ評価高かったから使ってみたけど、ちょっと使いづらいなこれ。クセが強い。
LoRaで特定人物の顔を学習させてるんですが、サンプルで表示される画像がピカソみたいなのばっかりです(まだ2万回ぐらいしか回ってない)
>>339 ツッコミどころ満載すぎて
何を2万回やったのか
512×512を10枚って何をやってるのか
>>340 Trainを2万ステップ(今は3万を越えてる)回した状態という事です
512x512は、縦横512ピクセルの顔画像で、それを10枚ソースフォルダに入れてTrainしているという意味です
あんまりしっかり検証したわけじゃないけど、Euler aだけモデルとの組み合わせもあるけどとんでもない絵を吐き出してくる印象だなあ。
>>343 情報サンクス
サンプラーはEuler a かEuler にしてました
帰宅したら変更してみます
学習画像の質にもよるし学習率やdimalphaによっても変わるしオプティマイザーの違いもあるし
>>345 デフォルトが10万回になってるし、ネット上の解説記事でも1~10万回ぐらいというのを見たので、1万回づつ追加学習させてました
2500ステップ程度でも過学習気味かなって感じることもあるけどな。
横顔だけ学習させたらピカソになるだろ。
>>349 DFLで使ってる顔画像が3000枚以上あるからソースはいくらでも増やせるんだが
ま、普通に考えて10枚は少なかったね
もっと増やして作り直してみるよ
低スぺでLowerオプションとか入れてると画像の質自体が落ちるのかな
突然画面が分割される周期に入ることってない?
>>353 「以前のプロンプトが残ってる気がする」の亜種という気がする
あの現象は、以前のプロンプトが反映されるシードが選ばれて起きると考えているので
シード値を-1じゃなくて適当な数値の決め打ちでしばらく生成するのはどうだろうか
>>354 なるほど、次症状が出たらやってみます!
全く同じ呪文とか設定でも端末によって生成されるイラスト変わってくる?
>>356 ハード的には石のメーカーが同じなら変わらない
ソフト的には全てがバニラなら変わらない
いずれも高速化(xformersなど)や低容量メモリ頑張る化(medvramなど)の要素とかで変わることはある
同じものを出そうとして出せなかった場合は
・自分の環境で変化してしまっている
・元画像が変化した状態で出している
のいずれか
後者なら同じものを出そうとするのはほぼ不可能になることがある
>>356 GPUが30x0以降とそれより前で結果がある程度変わるという話はある
検証した画像もあったよ
CoreMLで走らせると速いが、絵柄がガラッと変わる。
1000~2500epochくらいでLora作って基本的には特徴をとらえたものが出来てたのでそれで問題ないと思ってたけど、同じ教師データで7000epochで作り直してみたら、気持ち描写が多少良くなった気がする。
基本的に、みんな目的というか、どういう用途でstable diffusion使ってるの?
Twitterでゴミみたいな画像垂れ流して自己顕示欲を満たす
マイナーで二次創作が少なかったり、エロ禁止のキャラとか
自分も最初はエロ目的だったけど、それだけだと思ってた以上に早く飽きてしまった。
>>363 自分が箸にも棒にも掛からないゴミだからってそう僻みなさんな
>>368 そういうのできるんだ。
風景用のLoraから作る感じ?
>>368 どんなモデルを使うの?
よかったら教えて。
>>362 ゲーム作っててその素材にしようとしてる
>>373 俺もそのつもりだったけど楽しくて無関係なものいっぱい出してるわ
Lora作る時に、1girlてタグがほぼ確実に生成されるんだけど、これも学習対象に入れといた方がいいのかなあ?
写真取り込んで着せ替えみたいなのができたらいいんだけどな。
>>376 正則化画像とか用意できるなら入れた方がいいんじゃない?
chilloutmixでAOMのlove juiceみたいにできない?
リアル系で肌がどんどんツルツルの陶器みたいになっていくの、何とか防げないものか。
LoRa作る時って、アップの写真だけ使う?
gtx 1650 superだけど、低解像度で1枚10秒ぐらいかかってるけど、すごいなこれ・・
今まで面倒だったからフォトショのバッチで長方形のまま学習させてたけど、試しに手作業で正方形にトリミングしたらLoRaの質がめちゃくちゃ上がった気がする。
>>383 使い始めて数週間だけど仕事以外はこれしかやってないわ
楽しみにしてた大人気ゲームが出たけど30分しかやらずだし、マジで沼だ
>>383 1年前に3060 12GBを買うとは先見の明があるなあ
そんな大容量のVRAMあっても使わんじゃろと言われていた
メモリもストレージも増えれば増えただけ使ってしまう
入門的にM2のMacBook Airで色々始めてみて低解像度でLoRAとpromptのみのシンプルなやつが1枚1分くらいで作られるんだけど3060 12GBだと速度的に全然違う世界観になる?
>>386 発売当時「VRAM使い切れるほどの性能持ってない、持ち腐れ」と酷評だったな
それがここまで評価逆転するとはわからないもんだ
>>388 うちが3060の12GBだけどxformer有効で解像度512x768だと8秒くらい
>>390 ありがとうだいぶ速いな
久しぶりにWindows環境揃えるかぁ…
>>386 実は「エロ動画をAIを使って60fps化」するために、1650superではVRAMが足りていないという事態だったので
VRAM12GBを用意していたら、Stable Diffusionのほうが渡りに船状態になった
科学技術を進歩させるのは戦争だが人間を進化させるのはエロだからな
エロ用途なら12GBはJAVPlayerで随分前から有効活用されてるよ
>>393 エロ自体は割とすぐ飽きたけどな。
逆に性癖を簡単に満たせ過ぎてなんかやばい気がするわコレ。
飽きてAVに戻ってきたわ
2次、3次ともにどのモデル使って良いかわからんようになってきた
エロ用モデルを作り公開する人達の意欲と使命感はどこからくるのか
少なくともM1やM2だとメモリが足りないよな。
>>399 好みによるから自分で好きなの選べとしか
>>400 めちゃくちゃヒットしたらアップデート版は課金制になるとか?しらんけど
俺には神としか...
>>400 自分好みの絵が出るモデルを作りたい→できたからみんなにも使ってもらって自分好みの絵を出してもらいたい
はとても普通のことだと思うよ
試しに768×768でLoRa作れないかなと思ったけど、グラボの性能が足りず無理だったわ。
>>404 情報量は増える
これは、
・目的の情報の取得も増えるのと同時に、間違って取得するノイズ(誤情報)も増える
という意味になる
だから、再現性が高まるのと同時に、制御も難しくなる
>>405 なるほどー。
再現度は上げたいけど今のところはSDに追加投資する気にはなれないので、しばし見送りかなー。
>>406 3050。
流石に無理があった模様。
>>407 3070の8GBは768*768でもバッチ1ならいけるけどなー
ちなみにメインメモリはどんぐらい?
lora学習は元がサイズバラバラだと内部でリサイズ処理する時にメインメモリも大事らしい
>>409 メモリも関係するのか。
メモリは32GB。
作業とかで余裕はまだあるけど、おいおい64GBに替えると思う。
CivitaiにLORAはあるよ
inpaintで、塗りつぶした範囲だけ変換後に色が暗くなってしまうのですが、なにか設定の仕方がおかしいのでしょうか?分かる方いたら教えていただけるとありがたいです。
>>414 俺もそういう感じのこと最初あったけど、最近改めてやってみたらそういう症状出なくなったな。
何が原因かは分からんけどももしVAE入れてなかったら入れてみるとかは?
なんだよこのスペック沼。
>415
量子グラボが誕生すれば、すべてのグラボは過去のものとなる
4060ti 16Gってどうなんだろ?
グラボ8GBを2枚載せて16G並列化できないもの?
やばい物に手を出してしまった。中毒性高いな…
>>425 それな。
いろいろガチャしているだけで時間が溶けていく。
グラボを高速化してもガチャの回数が増えてしまうだけかもしれない。
>>423 VRAMだけで性能が微妙
3070以下なんじゃないかと言われてる
>>430 4060ti 16GでAI絵始めようと思ってたけど
3060 12Gでも良い気がしてきた
まぁ4060ti 16G出てみないとわからんけど
あれほど酷評されてた3060 12Gが化けたんだから4060も様子見やろなぁ
ゲーミングPC持ってて良かった🥺
コンピュータ歴はかなり長いけどオンボのグラボしか使ったことないよちよち歩きのグラフィック分野の初心者なんだけど。
見てないけどwebで動かしてるか推論だけ軽量モデルでやってるんじゃね
cpuでも行けるけど10分単位で待つからガチャ効率ものすごい悪い
>>434 グラボだけ高性能にすればいい
メインメモリも増やした方がいいけど
それ以外は モデルを SSD に入れた方がいい
これだけだね
>>425 バッチの数多くするのではなく、数回ごとにプロンプトを変えてトライアンドエラーをしていくと時間が溶ける
SDいうても、基本的に登録されてるプロンプトしか反応しないような感じだから、自由度の高いコマンド式AVGやってるような感じがあるよな。ずっとやってると。
マシュマロみたいなおっぱいがどうも苦手だから薄く血管浮かせたいんだけど、どうプロンプト書いてもダメ
多分チェックポイントが学習されてないんだろうね
SD使ってみてハマってるわマイクラ並の時間泥棒
>>445 LoRAの管理だったらcivitai helperが便利だけど違う話だったらごめん
>>446 i5の超貧弱CPUにGPUオンボだし、どうせ起動すら出来んだろうと興味本位でDLしたのが運の尽きだった
低解像度でも生成に1枚10分以上とかありえない遅さなんだろうけど、まだ物珍しさが勝ってるから
常にに何か生成しながら別の作業する癖がついてしまって、最近はとうとうPCの通販サイトまわって
GPUスペックと価格を眺める毎日に・・・これが沼の入口か
>>450 指定した性癖通り出てきたら脳汁出るよね
それが沼コースへの始まりだったわ・・・
SD用のファイル管理ツール作ったけど需要あるかな?
https://github.com/hanachanX/ImageFileEditing python初心者がからいろいろグダグダだけど。
とりあえずリリースからだれにも見向きもされない。
>>453 README.mdにツール稼働時のスクリーンショットを何枚か貼りつけてみたらどうかな
文字だけだとどうしても人目は離れちゃうかもしれない
ただいろいろ面倒な人も見に来るかもだから画像が映り込むときは画像全体にモザイク掛けるかよそから持ってきたサンプル画像集の画像とかに差し替えするのがいいかもしれない
とりあえず画像貼っといたけどなにせtkinterだからUIがショボすぎて画像載せるのためらうわ
>>450 You グラボ 買っちゃいなよ CV ジャニー喜多川
SD使い始めてまだ一月弱だが、ふとoutputsにある画像データの容量見てみたら10GB超えてた。
>>459 オートセーブを無しに、気に入ったのだけセーブ。
>>453 EXE化したので良かったら使ってみてください。
cloneしてくれた人が5人ほどいるみたいで感謝
AI川みたいなクッソリアルな質感とかどうやったら出るんだろうなあ。
低スペは解像度の上限が下がるけど質感そのものは変わらんでしょ
高解像度にしたらしたでAI「もう何人か書けるスペースあるから描いとこ!!」
丸出しじゃなくてチラ見せしたいのに、チラ見せのプロンプト追加するととんでもないです場所から生えてきたり、服がその部分の形にトランスフォームしたりする
隙間を埋めたくなるAI
Photoshopでもいよいよfireflyが導入されたけど、案の定ガチガチに規制してるな。
GeForce Game Ready Driver 532.03 WHQL
https://www.nvidia.co.jp/download/driverResults.aspx/204972/jp This new Game Ready Driver provides the best gaming experience for the latest new games featuring DLSS 3 technology including The Lord of the Rings: Gollum.
Additionally, this Game Ready Driver introduces significant performance optimizations to deliver up to 2x inference performance on popular AI models and applications such as Stable Diffusion.
studio用じゃなくてgame用ドライバなんだ。
453です
Stable Diffusionって
>>475 ありがとう、そのままstudioでいきます
もしsteamとかに興味があってstudioのままなら悪影響でるのかしら
もの凄いアホなこと聞いてるかもしれないがGPU内臓CPU詰んでる場合ってオンボードから画面出力した方がグラボに負荷掛からなくて生成速くなったりするのだろうか?
近影にすると高確率で自撮り風になるな
>>477 この質問 3000回目ぐらいだけれども
ほぼ変わらない
>>479 3000回目を飾ってしまってすまない…
そんな気にしなくても良い感じなのねありがとう
使えるビデオメモリが増えて、解像度は少し大きくできるけどね
フルHD 3画面で使っているけど、
どうでもいいエロ画像のためにグラボの値段吊り上げてるのはお前らか
マイニングと違って1人1~2枚あれば充分だから影響は少ないんじゃないか?
画像生成AIなんてものに手を出している人はマイニングに比べたらずーっと少ないだろうしね
俺はAI画像生成のこと知って初めてGPU絡みでマイニングってもの知ったぞ
マイニングするくらいならアート作品作ろうってプログラマの人が言ってた
マイニングはすぐ金になるけど、画像は自分で販路を開拓しなきゃならないからなぁ
そうそう、グラボに投資してお金を稼ごうとしたとき、画像生成AIはコンテンツの制作と販売もやらなくちゃいけない
masactrlだけいくらダウンロードしても反映されないんだがなにが悪いのかな?コミットとかわかる人教えて
GTXで2分かけてできあがる画像を何十枚も作ってたら朝日を見て寝るようになったわ
昨日まで問題なかったのに、いきなりin paintが使えなくなった。
再起動したけど、ダメだった…。
ごめん、更にもう一回再起動したら治った。
不具合で最高の出来ができたあったと後で気づいた時の悲しさ
しかしなんでprompt通りのもの出せないんだろうなこいつ
無能はできないことがあると、他人や道具のせいにする
けっきょくモデルとLORAの知ってることしか出ない
そもそもintelligence必要ない支持にすら従えないのはなんでだ
キミは最近知ったんだろうけど、基礎的なことはもうとっくに散々語り尽くされている事なので、関連スレや過去ログでも読んでおくれ
taggerを入れようとしたが、インストールはできたのになぜか表示されない・・・。
モデル毎に対応してるトークンリスト欲しいよね
このソフトスマホやタブレット端末でも出来るように成れば良いのに
さっさと進化させて加工しすぎたグラビアアイドルから脱却してくれ
>>508 ・自宅PCで動かして外から使えるようにはできる
・mage.spaceなどStable DiffusionのWebサービスを使う
>>509 モデル作者がそのように作るからであってAIの責任じゃない
要するに利用者の気持ち悪さが反映されてるだけ
ろくに理解していないことを背伸びして語らんでよろしい
>>508 iPhoneだといくつか移植されているよ。
でもなぜか同じモデルを使っても同じ絵が出ない。
1枚1分くらい。
>>504 そんなめんどくさいことしなくてもまともなもの出せるようにしろ
使ってる人間が一番intelligenceがないというオチ
>>453 R-ESRGANやCARNv2による超解像度変換機能を追加したので使ってみてください。
(CUDAが使えないと変換にかなり時間がかかります)
>>453 readmeのmarkdown英語で書けるのが優秀
ルール的にgitに上げるなら英語でreadme書かないといけないの?
WD14 Tagger、urlからインストールしてinstalledの所にもあるのにリロードしてもタブが追加されないのは何故だろう。何回も入れ直してもタブが増えない。
今まで起動してたんだけどなぜか
解決しました
>>517 がんばっている人はいる
なんJNVA部★216
http://2chb.net/r/liveuranus/1685500098 95 名前:今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ efe8-S+HU)[sage] 投稿日:2023/05/31(水) 14:07:26.15 ID:YMQeTjXL0
サンイチBBA
258 名前:今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ 0b12-qtTw)[sage] 投稿日:2023/05/31(水) 21:01:12.88 ID:bvv13YaH0
おはDはTwitter勢がやたら上手でかなわんわ
最近始めました
>>527 フレディ・マーキュリーが出ても困るよな
AMD Software: Adrenalin Edition 23.5.2 Release Notes
https://www.amd.com/en/support/kb/release-notes/rn-rad-win-23-5-2 Performance optimizations for Microsoft Olive DirectML pipeline for Stable Diffusion 1.5.
inpaintで修正かけた画像を、inpaintに転送し直してさらに修正かけようとすると、修正済みのところも影響受けるよな。
>>531 あれねえ、転送されてもマスクがクリアされない仕様のようなんだよね
だから転送前にインペイント領域の右上にある×ボタンを押して全部クリアするようにしてる
数日前に始めたけどむっず
一方画面にオチソチソ出したくて(penis:1.4)とか入れると7割フタナリになる俺がいる
LoraとかLyCORISのセットしても指定したキャラとか人がうまく反映しない
パラメータ指定するメタAI出たらお前らお払い箱だぞ
AI「お仕事お疲れさまでした、今日の抜きプロンプトはこれでいかがですか?付き合い長いですから好みは知ってますよ
最近始めたけどAIフォトやばいねこれ完全に写真じゃん
AIによる技術が発達し、動画などのリアルタイム自動生成ができるようになった今
>>535 こちとら肩からオッパイ生えてきたりしてるぞwww
パイ協調もっとしたいから
まんま人間の欲望が暴走したマッドサイエンティストの世界だよな。
>>546 ネガティブにextra各種入れていても召喚するから困る
合法ガチロリ画像が大量にうpられてる場所教えてください
父を吸う呪文を連打しても赤子しか召喚されないけどどうしたらいいんだろうw
>>552 NSFWのモデルでNSFWのプロンプトを入れるとか?
balloom_mixってLoraじゃなくてモデルなの?
一度クリーチャータイムが始まるとパラメータ変えても抜けられないの呪いだよな
>>557 俺もよくなるけど、VRAM 8GB、12GBの人でもなる?
俺は4GBだから良くなるものだと思ってとわ
便が出てくる場所間違えるのなんとかなりませんかね…
夜中に生成してると不意に顔面崩壊クリーチャー出てきたときびくってなる
>>559 ベンが出てくるとこ3箇所付いてて、そればっかりでてくるんだが…
奇形しか出ないの勘弁してくれ
BracingEvoMix、なかなか良いな。キレイ過ぎないところが良い
モデルによって極端な年齢操作が効かないのあるな
>>564 そのページでゆってたけど全く1からモデル作るのはやっぱよほどの環境がないと無理なんだな
だからみんな似たようなマージモデルをこぞって投稿してるわけだ
>>564 なんかガビガビしてるというか、昭和ぐらいのサイケなテイストを感じる。
扱い難しくない?
あと、俺の環境だけかもしれないんだけど、全く服を着ない…。
>>571 最終的にはそれもしたけど脱いだなあ。
何が悪いのかと思ったんだけど、BracungEvoMixのダウンロードページに書いてあった推奨のネガティブプロンプトを「削除」したらまともな動作になった。
強調が多かったからおかしいなとは思ってたんだけど、まさか推奨のプロンプトが悪さするとは思わんからさ。
わずか1日で好みの10歳から13歳くらいの女の子10000人の召喚に成功。まだ全員確認できてないくらいだ。
そう思うなら暗号化するなりして見られないようにしときなさい
v1.3.xとv2.x両方使い分けてる人いる?結構違うものかな?
浪費のきっかけにならないよう4090にはしなかったんだね、えらい
EasyNagativeを使い始めてから、プロンプト数がかなり削れて画質が上がったけど、これって具体的にどういう効果があるのかな。
いい感じの画像ができたので、SD使い始めの時にちょっとしか使わなかったアップスケーラーを久々に使って見たが、微妙に顔つきとか細かいところが変わってしまってコレジャナイ感が。
>>582 ノイズ除去強度を下げるんですよ
あとアップスケーラーはLatent以外にする
新Mac Pro買うとリアルタイム動画生成できるってマジ?
これすごくない?
>Vision Proを装着している他の人との、FaceTimeでのビデオチャットも体験してみた。相手はゴーグルをつけた状態で現れるのかと思ったら、付けていない状態で現れた。これ、実は機械学習で作られた合成映像だ。
>あらかじめVision Proのカメラで自分の顔をスキャンしておくと、スキャンした顔に内側についたカメラで撮影した目を合成してゴーグルをつけていない状態の顔を再現してくれる。しかも、リアルに表情も再現してくれるのだ。
「Apple Vision Pro」を先行体験! かぶって分かった上質のデジタル体験(2/3 ページ) - ITmedia PC USER
https://www.itmedia.co.jp/pcuser/articles/2306/06/news208_2.html >>584 なんJNVA部★219
http://2chb.net/r/liveuranus/1685975035/170 170 名前:今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ 0228-5Ku2)[sage] 投稿日:2023/06/06(火) 13:40:53.50 ID:VEid/mmo0
>> 161
m2 mac book air 24Gで生成してるワイからの忠告
それだけに使うならやめた方がいいよ
CUDA使えないってのが痛すぎる
512サイズの画像1枚生成するにも数十秒かかる
ほとんどの拡張機能はmacでも動くけどそれでも一部動かない機能があったり全く動かない拡張があったりするので自力で対応しなきゃならない
>>590 512四方の画像出すのに100秒かかるワイ咽び泣く
BracingeEvoMix、基本的に脱ごうとするバランスが良いな
始めて2週間全裸絵作りすぎてなんか自分の中で全裸の価値が薄れてきた
分かる
美女が汗まみれで柔道着を着て下着無しでチラッと見える最高の作品ができた
複雑なポーズさせようとすると、体も顔面も人外になっていく
>>557 多分Chromeのメモリバグかなんかだと思う
ExterNetworksでLora読み込めなくなってエラー吐いたりしてたけどPC再起動とかしたらなおった
>>558 8GBだけど少しサイズを大きくしたら共有メモリ使いだしたからそれが原因かも
Hires. fixしようとしたら32GBを使い切って合成途中で中止されたわ
いいかい、良く聞くんだ
なるほど
Don't worry, I'm wearing・・・
>>602 underwearどころかunderwareと書き間違えてた
software、hardwareからつい
ゼロからプロンプト書いてるの?
手軽に並べられる単語group shotだけど
Loraってwaitを高くすれば必ずしもモデルに似るって訳じゃないし、高く設定すると画像崩れまくるってのはもう散々身をもって知ったんだけど、どうしても作成画像がモデルに似ないと数値上げちゃうよなあ。
ControlNet使いはじめてからアダルトサイトでポーズ素材探す日々
人体のポーズ数。
トークン数、基本的に75におさまるように作ってるけど、オーバーしたからって即おかしくなるようなこともないのがかえって難しいな。
>>453 pythonの勉強のために作ったけど誰一人として使ってくれないw
tkinterじゃあUIが古すぎてダメか。CustumTkinterにしてもだめかな。
なんか改善案みたいなのあると勉強になるからissueでもください。
>>619 75超えた分は次のステップに回されるとか?
75-150トークンは実質半分のステップで生成しているとか思ったけどどうなんだろう
depth libraryを入れたらLoRAを読まなくなってもうた
あるある
しばらくするとWinError 10054通信が切れたってログが永遠に出続けるんだけど
bad nippleで変な位置から生えるの防げる?
>>630 結論から言うと、防げない
(防げることもあるかもという程度)
途中送信失礼
>>630 結論から言うと、防げない
(防げることもあるかもという程度)
乳首は「乳首を描くに適切な周囲」があれば勝手に描かれる
だから、妊婦のへそも乳首に適切な環境に該当する(膨らんでいる頂点である)ので乳首化しやすい
対策は、「(そこは乳首ではなく)ほかの要素である」と明示すること
前出のへその場合は「へそをちゃんと描け」と命じることで乳首化を防ぐ
方法論は無数にあるので、ご自身で探されたし
bad系は形状だと思う
分裂とか多人数が出るのを必死こいて防ごうとしてるのに、二人だったのが四人になったり、ずらっと横並びでキメられたりするともう逆に笑えてくるな。
一般的なクラスのGPUだとBatch sizeはほぼ無理なんかな
>>635 足りてないのはビデオメモリ
3050でも解像度小さくすればBatch sizeは増やせる
Latent Couple導入でいろんなサイト見ながら
>>619 Diffusers使いだけど少し前 (ver0.15.0) からDiffusersはCompel対応になっている
-----
Stable Diffusionパイプラインが生のプロンプト埋め込みを受け入れるようにします。
適切と思われる方法で埋め込みを自由に作成できるため、ユーザーはプロジェクトで
重み付けを表現するための新しいアイデアを思いつくことができます。
・重み付けされた埋め込みを作成するための高レベル ライブラリとして、
「compel」を採用しました。
-----
試しにコレ入れてみたらワード数の壁簡単に突破したわ、いくらでも入るみたい
画像のサイズ最初から大きくしすぎると、破綻した絵が出やすいよな?
>>642 それの導入方法わかりやすく説明してるとこありますか?
>>643 ドットが小さいから物体の大きさに対してずれるドットの数が大くなる
1ドット違うことは倍の解像度だと4ドットくらい違うことになる
詳細なグラフィックになればなるほど書き込み量も多いから破綻がわかりやすくなる
スケールプラグインのウルトラサンプリングで補正をした方がきれいになるかもしれん
ちなみにフォトで画像を2倍にしたらそっちのがきれいに見える気がするから
GIMPとかでシャープしながら解像度を倍にしたほうが結果的には早くいい仕上がりになるかも
>>644 最新のDiffusers(v0.17.1)での対応を日本語で説明しているのはまだ見つけていない。参考にしたのは下記3つ
(1) ttps://note.com/npaka/n/ne1bbe64fb5cd (日本語)
8. ウェイトプロンプト、 のところ
(2) ttps://touch-sp.hatenablog.com/entry/2023/06/01/115745 (日本語)
(3) ttps://pypi.org/project/compel/ (英語)
0.1.10 - add support for prompts longer than the model's max token length.、のところ
(1)ではCompelの導入方法については書いてあるけど肝心の長文を流し込むためのオプション (truncate_long_prompts=False) のことが書かれていない。
(2)ではしれっとそのオプションが使用例の中に書かれているんだけど今のバージョンだとこれだけでは動かない。
(3)はCompelの公式HPだけど、ソコにはこのオプションを有効にする時にはpromptとnegative_promptを同じ長さに調整するために、compel.pad_conditioning_tensors_to_same_length() を使って変換しろとなっている。これで両方を一気に変換すればソレ流し込んで無事に動いた。(3)のCompelのところにの書かれている例を真似するだけで十分みたい。
いまはMultiControlNetでcannyとpose両方使いながら長文流し込んでいる。以前はcustom piplineで切って流したりしていたけどMultiControlNetではcoustom pipelineは使えなかった。ので新たに対応したCompelで変換して流し込んでいる。
ややこしいなあ。
ぶっ続けで画像生成してると1日に何回かPCというかグラボが落ちる。
ハードを極限までぶん回すとトラブルが顕在化しやすいって話だろ
HWiNFOでも入れて常にCPUやGPUの温度チェックするとか
>>649 そんなことは一度もなったことございません
>>649 挿し方甘いのかも、俺もなったけど挿し直したら改善した
>>653 もしそれなら、初期不良だな。
今のPC買ってから一回も中触ってない。
想像であーだこーだ言ってないでイベントログ見なさいよ
トラブルシュートに無知なだけ
>>650 、お前のことだよ
ロゴありの画像を学習させてのもアホだけど
>>658 そんなモデルを使わないようにするしかない。
くそう
img2img系、サクサク動く時もあれば壊れたんか?ってレベルで遅々として進まない場合とがある気がする。
>>658 そもそも何千万とか何億とかいう画像数学習させてんのにわざわざ選別するわけないね
文字が認識できないのはレベルが低い、というのは分かるが
>>658 ネガティブプロンプトにtext、signature、watermarkなんかを入れてみては
>>665 しかもAppleシリコンはCPUとGPUでメモリ共有なんだよ。
これで4Kモニターに繋いでweb UIは厳しい。
こんな用途で使うことになるとは思っていなかったからね。
書い直してもいいのだが、M2系列ではどの程度のを使うとどれくらい速くなるのか、経験者の意見を聞きたい。
>>668 NVIDIA積んだPCを別に用意するのがずっといい
フロントエンド(ブラウザ)はMacのままにできる
俺は4090をUbuntuで動かしてMacから使ってる
M2 16GB(Air)で動かしたことあるけど遅い
中古で5万円台で3060積んだPC売ってたから買おうかと思ったんだが、i5のメモリ16GBだった。
>>670 3060でもVRAMが8GBだったりはしなかった? 12GBならなかなかかも
普通にWindowsが動いてもたつくことなく使えるならStable Diffusionには十分と思うよ
>>670 自分paypayフリマでRTX3060 ghost 28500円でかなりお値打ちだったなと思うので全部込みで50000円台なら有りじゃない?GTX1660superからの乗り換えだけど今のところ全く不満なし。
>>669 なるほど。
ubuntuでもいいんだな。
エロ目的で使ったが1週間で飽きたな
clipとcfgいじり始めたらもう立派なsd沼だ
大体のモデルはあれこれ凝ったもの書き込んだところで理解してくれんからな
普通に実用ツールとして使ってるわ
>>678 「生成が検索に取って代わる」てやつやね
つい最近NMKD版というのがあるのを知ったんだが、webui と比べてどう違うのか分からない。知ってる人いたら教えて。
>>681 質問スレのテンプレから
【StableDiffusion】画像生成AI質問スレ13
http://2chb.net/r/cg/1686751262/4 >Q3:NMKDと1111、どちらをインストールしたらいい?
>A3:NMKDはインストールは楽だが機能とユーザー数が少ない。1111がおすすめ
NMKDは1111と同時期に開発が始まったまったく別のプログラムだから互換性はないよ
>>682 あざっす。
調べてみた情報だとあんまり具体的なのがなくて、便利っぽいようなふわっとした情報しかなかったから試してみようか悩んでたとこだったので、参考になった。
AUTOMATIC1111/stable-diffusion-webuiのプレビューエリアをでかくしたら快適になった。
どうぞおっそわけです。
1.「インストールフォルダ\sd.webui\webui\」にテキストファイル(user.css)を新規作成
2.下のテキストをコピペして保存
3.再起動
div:has(+ #tab_txt2img){
width:541px;
}
#txt2img_toprow, #txt2img_extra_networks{
width:541px;
}
#txt2img_settings{
max-width:541px;
}
#txt2img_results{
position:absolute;
top:-200px;
left:541px;
width:calc(100% - 541px);
}
#txt2img_gallery{
height:900px;
}
#txt2img_gallery > .preview > img{
height:900px !important;
object-fit: contain;
}
#txt2img_gallery > .preview > div:last-child{
top:860px;
}
たしかに縦長画像の時に寂しいものがあるよね
>>686 だいたいそんな感じ
user.cssは誰か使ってくれてるかな
>>687 has擬似クラス使ってる人初めてみた
firefoxが対応していないとかてあまり興味なかったけどしてるんかな?
firefoxは正式対応してないみたいだね
>>685 自分は意味は分かってないんですが
メニュー系が全部左に集まってるのも操作しやすくていいですね
出力する時の解像度ってどうしてる?
480x480で作成2分かかるワイが来ましたよ
どでか1個づつでもいいから動作確認ははよせえ
ナーロッパのキャラ・モンスター・背景生成しまくればなろうコミックの生産効率100倍くらいになりそう
背景はあかん
>>690 使ってくれてありがとーう
ほかの皆も使ってくれー
>>691 512×768か768×1024
たまに胴体が妙に長いとかあるけど
>>692 もったいない、今すぐ自作しろ!
2分が5秒になるから今すぐだ!
ところで480×480が2分かかるGPUはなに?
>>700 GTX 1650、aDetailerあり、hiresしたら4分かかるけど80%の確率で落ちる
いやいや5秒なんてさすがに無理でしょ・・・え?4090とかならできるの?
>>698 2秒の方が普通だからネタじゃなくてただの見間違いでは?
>>701 なんの煽りか知らんけど生出力レベルのプロンプトなら3050でも6~7秒だぞ
Hiresは重いけどADetailerもつかってStep20ならそこそこのプロンプトでも1分で出力できる
3060ならおそらく40秒台4090なら20秒切るくらいじゃね
めんどくさいからって2分を選ぶ思考が分からんな・・・
>>701 5秒どころか3秒だった
あっしまった、adetailer使ってないや。もうちょっと待ってて
>>705 のつづき
480×480+Adetailerで6秒
480×480+Adetailer+hiresで23秒
これで自作する気になった? ああもったいない、3060が泣いとるぞ
roopってのを試してみようと思ってvisual studioのインストールかりやったけど、エラーを吐き出したり出さなかったり、一部の機能が使えなくなったり。
なんかよく分からんままに、エラーとかはおさまったけど、肝心のroopの項目が表示されないわ。
もう買ってあるんだったら組むだけじゃん か
昔はワクワクしたけど最近は年取ってめんどくさくなったわ
>>697 お前CPUで30分-1時間以上かけてる俺にケンカ売ってんのか?!
え?GPU使わずにCPUと物理メモリでSDって使えるの?
>>714 今は違うけど始めて1か月くらいは俺もCPUでやってたよ
>>716 グラボを買うお金がなかったのか
GPU の設定はわからなかったのか
それで違うと思うんだが
>>717 どっちでもない
グラボがかなり古いradeonだった
toolkitたのしーw無駄を削るって行為にハマる
すいません、かなり初心者的質問及び間抜けな質問になるんですが、SDのバッチサイズで使用されるVRAMとはグラボのVRAMということなのでしょうか?
https://youtube.com/shorts/kUWnuY2VpH4 このSDで作ったというAIダンスめっちゃ安定(顔が変形したり色が変わらない)してるんだけどどういう仕組み?
>>723 ありがとうございます。
助かりました。
3060の8GBなのでどうなのだろう?と思いました。ありがとうございました。
>>722 RAMはランダムアクセスメモリの略称でこれはPCのメインメモリを指してる
VRAMはビデオRAMといってグラフィックを扱うメモリのことでGPUはこれを搭載している
よって一般的にはグラボメモリのことをVRAMと呼ぶ
メインメモリをVRAMの代わりに使用できるシステムがあってVRAMが足りなくなるとメインメモリを変わりに消費してVRAM代わりに使うことができる
PCのメモリを全部使うとOSがフリーズしてしまうので全部使う仕様にはなっておらず半分まで使えるようになっている
使用されるVRAMというのはGPUが処理するに必要とするメモリなので普通はGPUのVRAMを指す
PCのメモリメモリをVRAMとして使えるかどうかは扱うOSやGPUの種類による
その仕様を利用してプログラムが扱えるように組まれてるなら扱うことができる、SDはデフォルトだと認識してる分のメモリを使うっぽいのでSDで補助的に扱えます
ただメインメモリの管理は本来CPUがしているので頻繁に共有するようなのはGPUメモリだけで扱うより速度が遅くなります
>>727 >PCのメモリ・・・中略・・・全部使う仕様にはなっておらず半分まで使えるようになっている
VRAM4GBグラボで、メインメモリ24GBだけどギリギリじゃないのに
プロセスが落ちたりするから不思議に思っていたけどそういうことだったのね
重ね重ねありがとうございます。
img2imgで画像解析してプロンプト出すと、結構な割合でrokkaku ayako って出てこない?
画家とかの名前が多いっぽいよね。
ここ二月ぐらい、グラボフル回転なので電気代が怖い。特にこれからエアコンも入れるしな。
>>712 正確にはもう無いにも等しいクソボロい内蔵GPU乗っかってるからCPUオンリーじゃないけど
メインメモリ12GBとインテルHD520で動かしてるよ!
>>717 単純に金がネー!
>>722 727に付け足し
メインメモリすら足りなくなるとスワップファイル作りだす
俺環だとスワップ領域すら不足気味なので使い始めた頃(2か月くらい前)は
他にアプリ立ち上げたりするとけっこう落ちてたけど最近はメモリ不足で落ちることは
滅多無くなった(※個人の感想です)
貧乏はどーしよーもならないので最近Colabにハマってる
別世界に来たようだw
えー?!そうなの?!
>>738 1枚10秒以内が理想だね
時間が余る時は画像を大きくする
colab→おせー
Colab垢2つ作って交互に画像生成すると体感的にかなり速く感じるよ
>>741 規約違反だからいつBANされてもおかしくないからね
>以下は、Colab ランタイムでは許可されていません。
>・複数アカウントの使用による、アクセスまたはリソース使用量の制限の回避
https://research.google.com/colaboratory/faq.html?hl=ja >737-738
しゅまん、You Tubeの解説どおりにSD入れてcivitaiでコピペしてるだけなんや
もしかしてグラボの性能が画質にもろに影響する?
俺も気になるんだが
>>748-749 GPUの性能によって出力結果が変わることはない
んだけど、10x0シリーズとそれ以降ではGPU内部のしくみの違いで結果が変わることがあるよ
>>749 16XX シリーズは画質があまり良くない
処理が重くて良い感じの絵だけどぼかしフィルター重ねた感じになるのはグラボ性能と関係ない?
「RTX3070の202209ロットは暖かみのある絵柄になる」みたいな
>>752 画像の具体例をcatbox.moeにアップロードして示してくれた方が話が早い
が、なんとなくエスパーしてみるとアップスケーラーを「Latent」関係にして、ノイズ除去強度を0.5未満など低くしていると出る症状かもしれない
「Latent」がつかないアップスケーラーにすれば解決するかも
>>751 俺も1650で速度以外は満足して3000枚ぐらい作ってきたけど(就寝外出中メイン)
同じピクセルで画質が悪いって実際にはどんな違いがある?解像的なもの?
画質にも評価の方法はあるけど、来月辺りに3060 12GBにするから同じプロンプトでどう変わるかを確認するのが楽しみだわ
一手間はかかるけど、img2imgの方が色々とコントロールしやすい気がするな。
i2iの書き込みの増やし方どうしてる?
Lora使わんと完璧なちんぽの形難しいんやけど、みんなどうしてる?
>>758 言ってる書き込みが何を指してるかは分からんけど、要素を出したいならプロンプト。
リアル系であれば、loraの設定を高めにしたら肌の質感が出るというか濃くなる感じ。
人体が崩れないとこまであげて、顔はまあもう一工夫して直したり保持したりだな。
>>725 元々がMMD等の3D映像で、SDではわずかなエフェクトを加えているだけでは。
GTX1660SからRTX3060 12GBに換装したけど、そこまで速くなった気がしない…
>>763 venvフォルダは削除して再構築はしたんだけど、それとは別?
--xformers をやめて --opt-sdp-attention --opt-channelslas あたりも試しなよ
>>762 うちも同じグラボで512×512だと一枚4秒だが、1660もそんな早いの?
>>767 コピペでショートしてtが抜けたやつをさらにコピペしたからどっちも間違ってるやw
--opt-channelslast
>>768 1660sで10数秒、3060でも10秒くらいかかるのよ
>>771 少なくとも vlam が2倍なので2枚同時に生成してくれ
プロンプト (Best quality, 8k, 32k, Masterpiece, UHD:1.2),Photo of Pretty Japanese woman,
しかし金のかかる趣味だな。
全てにおいて夢中な時は楽しい
昨日RTX3060に換装した者やが、高解像度で複数枚生成すると2~3枚おきに真っ黒な画像が生成されるんやが解決法ある?
>>778 黒い画像が出るのはVRAM不足のはず
どのくらい高解像度でどのくらいの枚数を生成したのかわからんけど、起動オプションに--medvramを入れてみては
あと--no-halfは--no-half-vaeのことかもしれない
(--no-halfはどういうときに入れるか自分は理解が足りないから--no-halfが正しいかもしれない…曖昧で申し訳ない)
エスパー回答するならHiresを使うなにつきる
>>779 >>780
ありがとう
Hiresは512*768の2倍、枚数はバッチ回数15バッチサイズ2でやって黒画像だった
medvramって生成遅くならない?
せっかくグラボ換装したから生成遅くしたくないなーって思って
>>784 並列処理なんじゃないの?
そこそこの質であれば、バッチカウント2、バッチサイズ1よりも
バッチカウント1、バッチサイズ2のほうが早いとか?
メモリ不足になっているなら真っ先にバッチサイズは1にすべきだろうに
>>787 ブイラムは 24gb のものを変え と言われているだろうが
その理由がわからんのか
>>784 俺も最初にいろいろ試したときに意味がないと判断して以降1だわ
初心者の頃だから判断を間違えた可能性はあるけど
バストアップぐらいならかなりプロンプトで無茶してもそれなりの形にしてくれるけど、膝上くらいの範囲描かせると一気に破綻するなあ。
バッチサイズ1でも Cuda の演算器リソースを全部使いきってるからな
>>791 画像生成している時にシステムモニターの
VRAMの使用容量を見ろって言ってんだろハゲ
>>793 同じシステムモニターの Cuda の使用量を見ろよ、童貞野郎
亀レスだけど
>>797 --no-halfと--no-half-vaeって何が違うの?
エラー吐いた時はsbが--no-half入れてみてって言ったから入れたら直った
初心者なんですが、二次元→三次元
>>800 ど、どういうこと?
こんなのをこんなのにしたい、みたいな具体例はあるかしら
イラストをimage2imageで実写にすることはできる
できる
早くメッシュで出力できるようになればいいな
少し前に、トークン数の上限の話なったけど、これみる限り今のバージョンだとデフォルトで上限は撤廃されたってことでおk?
https://yuuyuublog.org/sd_token/ 普通に質問やで。
もう数か月前のバージョンから75超えたら上限150みたいに表示されて数回に分けてトークン処理するようになったと思うが
俺も5月から始めたけど当時から75/150は実装されていたな
>>805 が聞きたかったのは見た目というか入力受付許容数だけじゃ無くて内部処理まで全部問題ないんかなってことだったんだろな
>>813 でも出来上がりを楽しみにしていてた思い出
xformaers導入したら、一気に効率が上がったな。
>>813 livePreviwewで生成の度に「クリーチャー出ませんように」と祈ってたわ
>>816 全力で願おうが、100万円のPCを使おうが、同じ確率で信じられないぐらい怖いクリーチャーになる
アナルの中の眼球と目が合うのが一番怖い
でもやっぱり性能良い奴の方がたくさんできそうだし、
>>820 解説本がソシムから出ているからそれ買いなされ
>>821 そんな不適切な使い方をしている奴がいるとは・・・
>>828 活動家のグレタばかり生成しているんだ・・・ってもう20歳かよ
全体的には満足なんですが顔が変わり過ぎてしまって…
コントロールネットのreferenceとinpaintingが楽
と思ったら、トークン数を75以下に直したら反映された。
急に調子悪くなるときあったけど本体を再起動したら治った
導入完了してコマンド入れてgenerate押したらボケた画像が出てきてよーし完成ってとこで白紙に戻されるんだけど何が悪いの?
私達~とかやめてもらえますか?
>>835 一応こっちもPCの再起動で治った。
プロンプトセレクター用のymlをいじってた時に何か変になったみたい。ってchat gptくんが言ってた。
PCの事よく分からんのだけど
>>836 「白紙に戻される」というから白だけの画像が出てくるのかと思ったら「戻される」だから違うんだね、出力を始める前のなにもない状態に戻るって話か
じゃあVRAM不足でしょう。コマンドプロンプトのほうにOutOfMemoryとか出てるんじゃないかな。
どんなよわよわGPUを使っているかわからないけど、起動オプションに--medvramや--lowvramをつけてあげるといいと思う
>>841 ついわざわざ調べちゃったけど入ってるGPUは「NVIDIA GeForce RTX 4060 Laptop GPU」でVRAMは8GB。
VRAMがやや心もとないけど画像生成はできるでしょう
起動オプションに--medvramが必要かもしれない
SD使ってても、正直不毛な時間なので極力触らないようにしようとするんだけど、ついついやってしまうな。
今日ついうっかり画像生成しまくって1日で3ギガ使っちゃったわ。
みんなは、って言うならそもそも大多数の人はSDを自前のPC上で動かしてるだろ
画像データチェックしてみたら45000枚越えで50GB。
pngは容量食うよね
pngは可逆なzip圧縮の応用でjpgは人間があまり気にしないところで色々投げ捨ててる不可逆圧縮なので圧縮率は段違い
多少サイズがブレるけど大きいなと思ったら可逆圧縮か
ゆうて50GB
記憶装置の値段が格段に下がってるのにその程度で愚痴るのか
>>854 別にそりゃ構わんのだけど。
仕事でも多い時は1日で20~50GBは使うことあるし。
ただ、HDD増やす頻度は下げたいし、余暇で使ってて、精々1024×1024の画像データで50GBいくとやっちゃった感はあるよ。
>>855 ワイの娘薬学部で年間200の6年サブスクやわ(ダブらん限り
>>857 成績が抜群なら1年無料とかの特典を狙えるかもしれんぞ
pngより小さくなった上に圧縮ノイズで逆に綺麗になってしまったjpgが
LoraとLycorisってフォルダ分ける意味ある?
>>860 ないよ。loraのフォルダにリコリス入れても普通に使える。
実写の絵がおかしくなるのはプロンプトがおかしかったりするからかな
コントロールネット覚えて沼った。てかオナ禁してる筈なのに続かなくなる。これがきつい。
>>862 リアル系は二次系と比べると、ちょっと無理な感じのプロンプト入れるとすぐ破綻するからなー
LoRA自体の追加学習についてなんだけど
あ、ファイルサイズが同じというのはおおよそという意味で
最初に画像生成するときのサイズって512×512でやった方がいいのかな?
>>869 SDが完全に初めてだったら、まずはデフォルトの512×512でやってみるのがいいんじゃない
そこからHires fix.やTileを使ったアップスケールを試していく感じ
>>871 そしたら出力解像度を少しずつ変えていく
縦長や横長にしてもある程度ならそのまま出力できる
960×960みたいに全体を大きくすると破綻した絵になりがちだけど、縦長や横長なら破綻しにくいよ
それをhires fixで2倍に大きくしたりする
さらにシードリサイズとか(拡張機能は不要)Tiled Diffusion(multidiffusionを入れる)とかを使ってみるとよい
必要最低限?と言われてるRTX3060で、
>>874 512×512のステップ20で1枚6秒くらい
これを512×768にして2倍にhires、adetailerと処理を増やしていくと1分とかかかるので、もうちょっと早いのに交換したい
breakdomainanimeをダウンロードしたいんだけどどっかにないかな
>>876 300円払えばダウンロードできるじゃん?
放置してると[WinError 10054] 既存の接続はリモート ホストによって強制的に閉じられましたってエラーログで延々埋まるやつ
RTX3070無印8GBでStable Diffusion起動するとビデオメモリが4GBまで使用率上がり、1024 1024でハイレゾ入れると8GBではりつき、大抵停止する。こんなもんすかね。
>>881 8GBならそんなものかなあ
いきなり1024×1024を出そうとするのは無理があると思うから、768×768くらい→Hires. fixから始めてみては
起動オプションに--xformersや--no-half-vaeをつけたりも忘れずに
あとはMulti Diffusionを入れてTiled VAEを使うと大きいのを出しやすくなるとかもあるよ
>>882 続き
--medvramもつけるといいかも
画像生成に時間はかかるようになるけどOut Of Memoryは出にくくなる
>>882 , 883
詳しくありがとうございます
感謝します
sdxl1.0出たから使ってみたけど1024*1024じゃないとまともな画像が作成できないから生成に時間がかかってだるい
んなこたない
小さいサイズの話でしょ
512x512だと意味のない画像しか生成できんかった。かといって1024x1024は時間がかかってしゃーない
一応乳首も出るから単純にnsfw系の学習量が少ないんだろうな。まあ、このへんはそのうち誰かがなんとかするだろ
薄着の指定が難しいな、勝手に全裸になること多し・・
薄着は難しいね。すけぶらも。あきらめて全裸と服画像を半透過で重ね合わせた。
薄着はprompt editingで前半裸、後半を着衣にすればよかった気がする
モデルカードを見るとBaseは128x128で作成するようなことを書いてるけど、128x128だとやっぱりまともな画像が生成されない
3060買ってチマチマ作ってて解像度を上げたら平均72度、最高86度記録するようになった。
もうトースター一歩手前!! (´・ω・`)~チリチリ
>>896 それはあくまでGPUの温度だろうから、vRAMやhotspotの温度は更に高い可能性があるので安心して震えるが良いぞ
>>896 3060ってそんな発熱大きいチップだっけ?エアーフローかなり悪い?
うちのシングルファン3060が同じくらいの温度だわ
>>901 GPUその温度だとホットスポット100度近く行ってる可能性あるし、VRAMも(3060はわからんが)確かに高い可能性はあるから、それで毎日長時間も回し続けるとってことじゃね
グラボのチップの最高温度は75°c
3060いいなあ。グラボ買う金がもったいなくてAWS使ってるから生成時間が気になってしかたがない
画像生成にとっては
depth-lib入れてると拡張全体が読み込まれなくなったので消したのん
無印SDは動いたが
今の時点だとSDXLは標準のモデルでわりといい感じに出してくれるというだけだなあ
XLはvram12Gでもきついらしい
変な質問で申し訳ない。
変な質問で申し訳ない。
うまくいかないなら別フォルダに入れて必要なファイル移せばいいじゃない
gitはよー分からんがgit pullしてアップデートしたのならその前に戻す操作をすればいいんじゃね
AWSでSDXLとその派生モデルをちょいちょい試してるけど、まだまだSD1.5の特化型モデルのほうが優れている気がするから様子見でよさそう
EasyNegativeとか強くすると関節とか肌とかが茶色っぽくなっちゃうの回避する方法ない?
調べてもわからなかったので質問させてください
https://wikiwiki.jp/sd_toshiaki/%E3%83%AD%E3%83%BC%E3%82%AB%E3%83%AB%E7%89%88%E5%B0%8E%E5%85%A5#webui このサイトの手順通りにwebui-user.batを起動しました
しかし
Model loaded in 9.8s (calculate hash: 7.3s, load weights from disk: 0.2s, create model: 0.4s, apply weights to model: 0.6s, apply half(): 0.5s, move model to device: 0.7s).
で止まってしまいます
https://note.com/uunin/n/n715256399038#52477e3c-4284-4164-a0fa-f4876f4aee81 この方法でも同じ場所で止まってしまいます
必要スペックは満たしています
指定の場所にDLしたモデルを置いています
もしよければ教えていただきたいです
お願いします
>>918 そこで止まるのは正しい動作だよ
その止まる行の少し上に、「Running on local URL:
http://127.0.0.1:7860 」みたいなのが出てるでしょ
そのアドレスへブラウザでアクセスするとWebUIが表示されるんよ
>>919 ありがとうございます
教えていただいた通りにしたらブラウザで開けました
どうしたらいいのかわからなかったので本当に助かりました
automatic v1.6.0 にしたらエラー出まくりだわ
Hiresfix は強制ONなのか?これ
Hiresfix と Refiner はこの欄を展開しなければOFFってことか
v1.6.0 でメインメモリの使用量が増加したのか?
アプデしたら生成ボタンの下にあった保存ボタンが消えたんですが
アプデしたら生成ボタンの下にあった保存ボタンが消えたんですが
Win11
>>927 ドスパラで新品で15万ってとこだから、中古なら7万~10万くらいかな
MultiDiffusionを使って2倍の解像度にすると
ちょっと分からんけど、アップスケールの方法は色々あるので
そもそも何がしたくていまだに MultiDiffusion なんか使っているか? ってところからだよね
バッチで大量に試作した画像の削除ってどうしてる?
ハズレかどうかは個人の主観なのにどう自動削除するのか
全自動は流石に無理だろうけど、こりゃハズレだなって思ったやつを選択したらそれと類似性が高い画像を削除してくれるようなやつなら行けそうじゃね?
ローカルインストールのwebuiでimg2imgでnsfwフィルター外すにはどうしたら良いの?
1.6にアプデしたらmov2movのタブなくなって動画生成できなくなったんやけど作れてる人おる?
img2imgってinpainting使わずに顔をキープする方法ってあるの?
いま使ってる古いGTXだと1枚生成するのに5分かかるからRTX3060 12GBかRTX4060かで悩んでてさ、
XLは発展途上だし、1.6の方が人気じゃないか?
現状のAI画像生成環境において4060(8GB)のどこに総合的な優位性があるのかマジで判らんぞ……
えっえっ??
昨年末くらいにv2.1まで出てるはずなのにv1.6が人気ってどういうこと…??
ごめんこのへんチンプンなんだけど、Stable Diffusion本体はv2.1で、そのGUI(web UI)のバージョンがv1.6ってことかしら???
ややこい…
ControlNetとやらもまたメモリ食いなの?
わからないなりになんとなくイメージしてる自分の使い方としては、
【手順1】512x512で大量ガチャ
【手順2】気に入ったシードを選ぶ
【手順3】そのシードだけアプコンしたり時間をかけて仕上げ
前提として手順1が8GBで事足りるならば、手順3のときだけ-–medvramや–lowvramをつけて遅くなってもストレス最小限でイケるんじゃないかなんて考えてるのだけど、考えが甘いかしら?
>>952 SDのベンチマーク結果だけみると4060の方が10%くらい速いみたいだけれど、SDXLだと3060が7倍速いとか。
SDXLに目を瞑るなら4060優位なのかなって思ってたんだけどそうでもなくなってるかんじなんですかねー
はっきり言って、そのどっちかで悩んでるんならメモリー多いの買っときゃ良いじゃん
>>953 その知識量で安易にグラボ買うのは悲しみの結末しか見えんわ
悪いことは言わんから情報をもっと調べるんだ
少しでもAI画像生成の情報を仕入れてたら、昨今で「4060(8GB)」なんて意味不明な選択肢に至ることはありえん
まあそれなりに安いのは確かだから分かって買うなら4060でもいんじゃね、オレは買わんけど
なお4070が幻滅されている理由は
かぁ〜〜〜!!!!!
もう3060でいいかって思えてきた矢先に、DLSS3対応ゲームで4060が2倍近いFPS叩き出してるのみたらまた心が揺れちゃったよ!
>>956 https://chimolog.co/bto-gpu-stable-diffusion-specs/ とかみて、SDXLを除けば4060の方が20%以上優秀っぽいから、ネイティブ高解像度が不要なら4060なのかなって思っちゃったのよね。
512x512だけなら8GBで不足することはない、とも小耳に挟んで。
なんか、今じゃない、が結論のような気がしてきた。。。
今じゃなきゃ次のRTX5000シリーズは2025年後半だが
>>959 もう好きにしていいぞ。周囲は別に困らんからな
そもそも「512で良い」発言が目立つ点とゲーム関連でグラツいてる辺り、AI画像生成もちょっとやったら飽きるやろう
ただ、日記は適当に切り上げるんだぞ
easy prompt selectorが歯車マーク「タグを選択」を押しても、YAMLファイルを選ぶプルダウンが表示されません。
今じゃないって結局目的が何もないって事でしょ
VRAMは30系40系関係なく最低12GB以上あった方が良い
エロならSD1.5
絵を描き出す演算時間が10秒でも2分でも変わらないから
基本的にAIはこっちの思考よんで絵を自動で出す訳じゃないんよ
それが描き出す絵柄とどう関係あるんだよ
高解像度の絵柄も満足いくちっこい絵ができた後にTiledDiffusion使って高解像度化するからまじで絵を見つける時間の演算処理なんて必要ねーよ
試したいだけだったらインターネットカフェでも
こういうタイプは安い3060で十分
>>962 yamlファイルはちょっとのミスでも開けなくなって、全てに影響してプルダウンすら開けなくなるからどれかのファイルのどこかしらの記述が間違えてるはず。
面倒かもだけど1つずつファイル入れて開けるか試すか逆に1つずつファイルを取り出して試す
ちなみにUIの更新(F5含む)だけじゃダメでバッチ起動時に読み込み直すから完全にUI自体の再起動必須
面倒だけど頑張って
VRAM不足でエラーだとか使えないだとかってのは、--medvramや--lowvramを付ければ解決ってもんでもない?
設定すれば行くんじゃねーの
金ない奴が4GBのVRAMとかで無理動かすのは勝手にやれば良いけど人に勧めるレベルの話じゃないだろ
>>977 その台詞、大分ブーメランだな…‥
上で演算時間どうこう言ってた人の台詞とは思えんぞ
実際3060と40シリーズの差は2-3倍程度だろ
恐らくほぼグラボ使わないでCPUで演算してそうだし
3Dのレンダリングもグラボ使わないで演算させると百倍超える時間かかった上に途中でノイズやエラー吐いてレンダリング止まる事あるし
4050て6GBよね
日記くんが、ろくに使ったことも無いのに妄想で推奨スペック語ってる状態だろ
とりあえず RTX 3060を買ってみては
このスレは進みが遅かったから、1は去年の8月27日なんだな
StableDiffusionが画期的でコラ画像が合法化?された元年と言ったところだろうか
>>985 そろそろ使いこなせよw
それともサブスクとかCG集売ってるから後続恐れているのか?
3060 12GB買えばとりあえず普通に使える
>>981 CPUの使用率は低いまま動かなかったよ、たぶん演算にはほぼ使ってない。
システムメモリはGPU共有メモリとして16GBくらい占有されとったけど。
次スレいらんだろ
v2.0、v2.1、SDXL、…と出ていても結局みんなv1.5を使ってるのはなんで?
SD1.5はモデルやLoRAなどの資産が桁外れに多いからね
ただ綺麗なだけの絵に意味が無いことは、AU画像生成弄ってる大多数が遙か以前に理解してるはず
1.5の資産を使い回せるよになったら
標準のモデルをひねりもなく使ったときにそこそこいい感じの絵が出ることだけがSDXLのメリットで
このスレッドは1000を超えました。
5ちゃんねるの運営はUPLIFT会員の皆さまに支えられています。
運営にご協力お願いいたします。
───────────────────
《UPLIFT会員の主な特典》
★ 5ちゃんねる専用ブラウザからの広告除去
★ 5ちゃんねるの過去ログを取得
★ 書き込み規制の緩和
───────────────────
会員登録には個人情報は一切必要ありません。
4 USD/mon. から匿名でご購入いただけます。
▼ UPLIFT会員登録はこちら ▼
https://uplift.5ch.net/ ▼ UPLIFTログインはこちら ▼
https://uplift.5ch.net/login
このスレへの固定リンク: http://5chb.net/r/software/1661568532/ ヒント: 5chスレのurlに http ://xxxx.5chb .net/xxxx のようにb を入れるだけでここでスレ保存、閲覧できます。 TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
>50
>100
>200
>300
>500
>1000枚
新着画像 ↓「Stable Diffusion YouTube動画>1本 ->画像>20枚 」 を見た人も見ています:・画像作成AI『Stable Diffusion』、GUI版が登場 Stable DiffusionはGDPR違反か?ネットの一部で話題に 【Stable Diffusion】今最もアツい画像生成AIが決定する 【悲報】アメリカの画家、画像生成AI「Midjourney」「Stable Diffusion」に対し集団訴訟 【AI】画像生成AI「Stable Diffusion」の上位モデル「XL」登場、より短い呪文で描写的なイメージを生成 [すらいむ★] 【速報】 DeepSeek、画像生成AIを公開 Stable Diffusion やオープンAIを超える画像生成の性能と自負、商用利用も可能 [お断り★] 【AI】テキストや画像から動画を生成するAI「Stable Video Diffusion」をStability AIが公開へ [すらいむ★] 【StableDiffusion】AIエロ画像情報交換54 【StableDiffusion】AIエロ画像情報交換48 【StableDiffusion】AIエロ画像情報交換31 【StableDiffusion】AIエロ画像情報交換51 【StableDiffusion】AIエロ画像情報交換33 【StableDiffusion】画像生成AI質問スレ21 【StableDiffusion】AIエロ画像情報交換35 【StableDiffusion】AIエロ画像情報交換49 ChatGPT-4とStableDiffusionを使ってbot作ってみた 【StableDiffusion】画像生成AI質問スレ26 【StableDiffusion】画像生成AI質問スレ20 【StableDiffusion】画像生成AI質問スレ30 【Unity直接関係ないけど】StableDiffusion作った 【Midjourney】AI関連総合9【StableDiffusion】 【StableDiffusion】画像生成AI雑談スレ3 【Midjourney】AI関連総合【StableDiffusion】 【StableDiffusion】AIパソコンスレ 質問・雑談2 【StableDiffusion】AI画像生成技術14【NovelAI】 【Midjourney】AI関連総合23【StableDiffusion】 【StableDiffusion】AIエロ画像情報交換24【NovelAI】 【StableDiffusion】AI画像生成技術7【Midjourney】 【StableDiffusion】AIエロ画像情報交換17【NovelAI】 【Midjourney】AI関連総合24【StableDiffusion】 【StableDiffusion】AI画像生成技術16【NovelAI】 【Midjourney】AI関連総合20【StableDiffusion】 【StableDiffusion】AIエロ画像情報交換12【NovelAI】 【StableDiffusion】AIエロ画像情報交換14【NovelAI】 【StableDiffusion】AIエロ画像情報交換16【NovelAI】 【Midjourney】AI関連総合8【StableDiffusion】 【StableDiffusion】画像生成AI質問スレ9【NovelAI】 【Midjourney】AI画像生成技術5【StableDiffusion】 【StableDiffusion】AI画像生成技術19【NovelAI】 【Midjourney】AI関連総合25【StableDiffusion】 【Midjourney】AI関連総合15【StableDiffusion】 【StableDiffusion】AI画像生成技術17【NovelAI】 【StableDiffusion】画像生成AI質問スレ24(ワッチョイ有) 【stablediffusion】AIでえっちな画像生成するために必要な技術教えて【Lora】 プログラマー僕今からStableDiffusionをデスクトップ環境で使えるアプリを作る 【ID無し】KPOP第5世代雑談★3【ILLIT BABYMONSTER KISSOFLIFE tripleS QWER MADEIN izna MEOVV】 【NovelAI】AIエロ画像情報交換 3【Waifu Diffusion】 Who do you love on High School Fleet(Haifuri)? 【PC】Appleの独自ファイルシステム「APFS」がまもなくFusion Driveでも利用可能に 「macOS 10.14」で導入か ヒプノシスマイク DivisionRapBattle RuletheStage どついたれ本舗 VS BusterBros!!!CinemaEdit 挿入歌シングル:Sunny Passion「HOT PASSION!!」、Liella! 1stアルバム「What a Wonderful Dream!!」が発売決定! トランプ「"TARIFF" is most beautiful word in the dictionary」安倍晋三「」⇐なんて言った? DreanDiffusion "What's this board" Lets talk about Ninja version 2.0 ★2 I wanna be able to write English without using translation tools 世界向けNHK番組のフェスにPerfume、布袋寅泰、SixTONES、日向坂46、BABYMETAL、蒼井翔太ら 日本ゲーム業界「ハアハアなんとかバイオとキンハが当たったぞ…」メリケン「Apex Legend!Far cry!Anthem!Division2!」 【苺Lifetime】SixTONES 237ズドン【oneST】 【速報】持続可能な射精目標(Sustainable ejaculation goals, SEGs)、決定 【ID無し】KPOP雑談★1020【LE SSERAFlM NewJeans IVE aespa NMIXX STAYC Kep1er BABYMONSTER】 【ID無し】雑談★603【LE SSERAFlM NewJeans IVE Aespa NMIXX STAYC Kepler NiziU XG BABYMONSTER】 【ID無し】雑談★687【LE SSERAFlM NewJeans IVE Aespa NMIXX STAYC Kepler NiziU XG BABYMONSTER】 【ID無し】KPOP雑談★969【LE SSERAFlM NewJeans IVE aespa NMIXX STAYC Kep1er BABYMONSTER】 【ID無し】雑談★817【LE SSERAFlM NewJeans IVE aespa NMIXX STAYC Kep1er NiziU XG BABYMONSTER】 【ID無し】雑談★762【LE SSERAFlM NewJeans IVE aespa NMIXX STAYC Kep1er NiziU XG BABYMONSTER】 【ID無し】雑談★710【LE SSERAFlM NewJeans IVE Aespa NMIXX STAYC Kepler NiziU XG BABYMONSTER】
12:42:17 up 97 days, 13:41, 0 users, load average: 7.22, 8.01, 8.37
in 1.8105499744415 sec
@1.8105499744415@0b7 on 072401





 (txt2imgで生成)
(txt2imgで生成)  (img2imgのinpaintで生成)
(img2imgのinpaintで生成)